|
2023 ─Ļ 8 į┬Ż¼Meta ║═ CMU łF(tu©ón)ĻĀ(du©¼)┬ō(li©ón)║Ž═Ų│÷┴╦═©ė├ÖC(j©®)Ų„╚╦ųŪ─▄¾w RoboAgentĪŻ▓╗═¼ė┌ DeepMind
Ą─ RT ŽĄ┴ą─Żą═▓╔ė├┴╦┤¾ęÄ(gu©®)─ŻÖC(j©®)Ų„╚╦öĄ(sh©┤)ō■(j©┤)╝»▀M(j©¼n)ąąė¢(x©┤n)ŠÜŻ¼┐╝æ]ĄĮÖC(j©®)Ų„╚╦į┌¼F(xi©żn)īŹ(sh©¬)╩└ĮńųąĄ─ė¢(x©┤n)ŠÜ║═▓┐╩
ą¦┬╩å¢Ņ}Ż¼Meta īóöĄ(sh©┤)ō■(j©┤)╝»Ž▐ųŲĄĮ┴╦ 7500 éĆ(g©©)▓┘ū„▄ē█EųąŻ¼▓ó╗∙ė┌┤╦ūī RoboAgent īŹ(sh©¬)¼F(xi©żn)┴╦ 12 ĘN▓╗
═¼Ą─Å═(f©┤)ļs╝╝─▄Ż¼░³└©║µ▒║Īó╩░╚Ī╬’ŲĘĪó╔Ž▓ĶĪóŪÕØŹÅNĘ┐Ą╚╚╬äš(w©┤)Ż¼▓ó─▄į┌ 100 ĘN╬┤ų¬ł÷Š░ųąĘ║╗»æ¬(y©®ng)
ė├ĪŻ
śŗ(g©░u)Į©ę╗éĆ(g©©)┐╔ęįĘ║╗»ĄĮįSČÓ▓╗═¼ł÷Š░Ą─ÖC(j©®)Ų„╚╦ųŪ─▄¾wąĶę¬ę╗éĆ(g©©)Ė▓╔w├µūŃē“ÅVĄ─öĄ(sh©┤)ō■(j©┤)╝»ĪŻ└²╚ń RT-1
Š═▓╔ė├┴╦│¼▀^ 13 ╚fŚlÖC(j©®)Ų„╚╦▓┘ū„▄ē█EöĄ(sh©┤)ō■(j©┤)üĒ▀M(j©¼n)ąąė¢(x©┤n)ŠÜŻ¼RoboAgent ätų°č█ė┌į┌ėąŽ▐Ą─öĄ(sh©┤)ō■(j©┤)Ž┬╠ß
GÖC(j©®)Ų„╚╦īW(xu©”)┴Ģ(x©¬)ŽĄĮy(t©»ng)Ą─ą¦┬╩Ż¼Č°▌^╔┘Ą─öĄ(sh©┤)ō■(j©┤)═©│ŻĢ■(hu©¼)ī¦(d©Żo)ų┬─Żą═▀^öM║ŽĪŻRoboAgentĄ─öĄ(sh©┤)ō■(j©┤)╝»╣▓ėą7500
ŚlöĄ(sh©┤)ō■(j©┤)Ż¼Ęųäeį┌ 4 éĆ(g©©)ÅNĘ┐ł÷Š░ųą▓╔╝»Ż¼░³║¼ 12 éĆ(g©©)╝╝─▄Ż¼38 éĆ(g©©)╚╬äš(w©┤)ĪŻ╗∙ė┌┤╦ąĪ¾w┴┐Ą─öĄ(sh©┤)ō■(j©┤)Ż¼Meta
▓╔ė├┴╦╚½ūįäė(d©░ng)Ą─öĄ(sh©┤)ō■(j©┤)į÷ÅVüĒī”öĄ(sh©┤)ō■(j©┤)╝»▀M(j©¼n)ąąą┼ŽóöU(ku©░)│õŻ¼═©▀^ Meta ╠ß│÷Ą─Ī░ĘųĖŅę╗Ūą─Żą═Ī▒
Ż©Segment Anything ModelŻ¼SAMŻ®üĒī”łDŽ±ųąĄ─▒╗▓┘ū„╬’¾w║═▒│Š░▀M(j©¼n)ąąĘųĖŅŻ¼╚╗║¾Ęųäeī”▒╗▓┘
ū„ī”Ž¾║═▒│Š░▀M(j©¼n)ąąą▐Ė─Ż¼ęį▀_(d©ó)ĄĮöĄ(sh©┤)ō■(j©┤)╝»öU(ku©░)│õĄ──┐Ą─ĪŻ
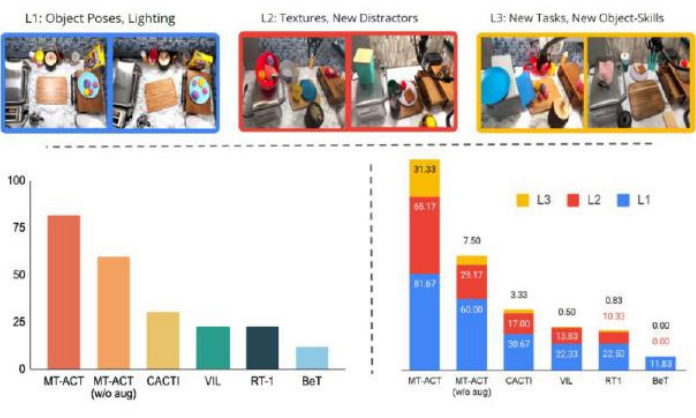
RoboAgent ĦüĒ┴╦öĄ(sh©┤)ō■(j©┤)ą¦┬╩Ą─╠ß╔²ĪŻMeta ╠ß│÷┴╦ MT-ACTĪ¬Ī¬ČÓ╚╬äš(w©┤)äė(d©░ng)ū„ĘųēK Transformer ▀@
ę╗īW(xu©”)┴Ģ(x©¬)┐“╝▄Ż¼┼cę╗ą®│ŻęŖĄ─ė¢(x©┤n)ŠÜ╦ŃĘ©┐“╝▄ŽÓ▒╚Ż¼RoboAgent ¾w¼F(xi©żn)│÷┴╦Ė³GĄ─śė▒Šą¦┬╩Ż¼▓óŪęį┌ČÓ
éĆ(g©©)Ę║╗»īė├µ╔ŽČ╝ėą│÷╔½▒Ē¼F(xi©żn)ĪŻMeta ī”Ę║╗»Jäe▀M(j©¼n)ąą┴╦┐╔ęĢ╗»Ż¼L1 ▒Ē╩Š╬’¾wū╦æB(t©żi)ūā╗»Ż¼L2 ▒Ē╩ŠČÓ
śėĄ─ū└├µ▒│Š░║═Ė╔ö_ę“╦žŻ¼L3 ▒Ē╩Šą┬ĘfĄ─╝╝─▄-╬’¾wĮM║ŽĪŻMT-ACT Ą─▒Ē¼F(xi©żn)’@ų°ā×(y©Łu)ė┌Ųõ╦¹╦ŃĘ©Ż¼
╠žäe╩Ūį┌Ė³└¦ļyĄ─Ę║╗»īė┤╬Ż©L3Ż®╔ŽĪŻ
|
