|
░ž┴ų╣żśI┤¾īW║═ Google Robotics łFĻĀĮY║Ž┴╦ Google «öĢr 5400 ā|ģóöĄĄ─ PaLM ┤¾
šZčį─Żą═║═ 220 ā|ģóöĄĄ─ Vision TransformerŻ©ViTŻ®─Żą═Ż¼╠ß│÷┴╦«öĢr┤¾ęÄ─ŻĄ─ 5620 ā|ģóöĄ
Ą─Š▀╔ĒČÓ─ŻæBęĢėXšZčį─Żą═ Ż©Visual Language Model, VLMŻ®PaLM-EĪŻį┌ PaLM ─Żą═╗∙ĄA╔ŽŻ¼
ę²╚ļ┴╦Š▀╔Ē╗»║═ČÓ─ŻæBĖ┼─ŅŻ¼īŹ¼F┴╦ųĖī¦¼FīŹ╩└ĮńÖCŲ„╚╦═Ļ│╔ŽÓæ¬╚╬䚥─╣”─▄ĪŻ
PaLM-E ▓╔ė├Å─ČÓ─ŻæBą┼ŽóĄĮøQ▓▀Č╦Ą─Č╦ĄĮČ╦ė¢ŠÜĪŻPaLM-E ų▒Įėīó▀B└mĄ─ĪóŠ▀¾wĄ─ČÓ─ŻæBė^▓ņ
Ż©╚ńłDŽ±ĪóĀŅæB╣└ėŗ╗“Ųõ╦¹é„ĖąŲ„─ŻæBŻ®Ż¼▐D╗»×ķ║═šZčį token ŪČ╚ļ┐šķgŠSöĄŽÓ═¼Ą─Ž“┴┐ą“┴ąŻ¼
ė├║═šZčį token ═¼śėĄ─ĘĮ╩Įūó╚ļŅAė¢ŠÜšZčį─Żą═Ą─šZčįŪČ╚ļ┐šķgŻ¼Å─Č°į┌╬─ūų║═Ėąų¬ų«ķgĮ©┴ó┬ō
ŽĄŻ¼ęčĮŌøQÖCŲ„╚╦ŽÓĻPĄ─Š▀╔Ēå¢Ņ}ĪŻ─Żą═Ą─▌ö╚ļ╩ŪĮ╗ÕeĄ─ęĢėXĪó▀B└mĀŅæB╣└ėŗ║═╬─▒ŠĮM│╔Ą─ČÓ─Ż
æBŠÄ┤aŻ¼╚╗║¾ī”▀@ą®ŠÄ┤a▀MąąČ╦ĄĮČ╦ė¢ŠÜŻ¼▌ö│÷Ą─ā╚╚▌ät╩Ūī”ė┌ÖCŲ„╚╦ꬳ╠ąąĄ─äėū„Ą─╬─▒ŠøQ▓▀ĪŻ
š¹éĆ▀^│╠▓╗ąĶę¬ī”ł÷Š░Ą─▒Ē╩Š▀MąąŅA╠Ä└ĒĪŻ
ęį┤¾─Żą═ū„×ķ║╦ą─Ą─ PaLM-E ▒Ē¼F│÷┴╦▌^ÅŖĄ─Ę║╗»─▄┴”║═ė┐¼F─▄┴”ĪŻčąŠ┐╚╦åT░l¼FŻ¼PaLM-E └^
│ą┴╦┤¾šZčį─Żą═Ą─║╦ą─ā׳cŻ║Ę║╗»║═ė┐¼F─▄┴”ĪŻĄ├ęµė┌Č╦ĄĮČ╦Ą─ČÓ─ŻæBą┼Žóė¢ŠÜŻ¼PaLM-E į┌├µ
ī”ø]ėąīW┴Ģ▀^Ą─╚╬䚯©zero-shotŻ®Ģrę▓─▄ėą║▄║├Ą─▒Ē¼FŻ¼Š▀éõīóÅ─ę╗ĒŚ╚╬äšīWĄĮĄ─ų¬ūR║═╝╝─▄▀w
ęŲĄĮ┴Ēę╗ĒŚ╚╬䚥──▄┴”ĪŻĮø▀^▓╗═¼╚╬äš╗ņ║Žė¢ŠÜ║¾Ą─ PaLM-EŻ¼┼cł╠ąąå╬ę╗╚╬䚥─ÖCŲ„╚╦─Żą═ŽÓ
▒╚Ż¼ąį─▄├„’@╠ßGĪŻ═¼ĢrŻ¼▒M╣▄ PaLM-E ų╗Įė╩▄┴╦å╬łDŽ±╠ß╩ŠĄ─ė¢ŠÜŻ¼Ą½ģsęčĮøš╣╩Š│÷┴╦ė┐¼F─▄
┴”Ż¼▒╚╚ńČÓ─Ż╩Į╦╝ŠSµ£═Ų└ĒŻ©┐╔ūī─Żą═Ęų╬÷░³└©šZčį║═ęĢėXą┼Žóį┌ā╚Ą─ę╗ŽĄ┴ą▌ö╚ļŻ®┼cČÓłDŽ±═Ų
└ĒŻ©ė├ČÓéĆłDŽ±ū„×ķ▌ö╚ļüĒū÷│÷═Ų└Ē╗“ŅA£yŻ®ĪŻ
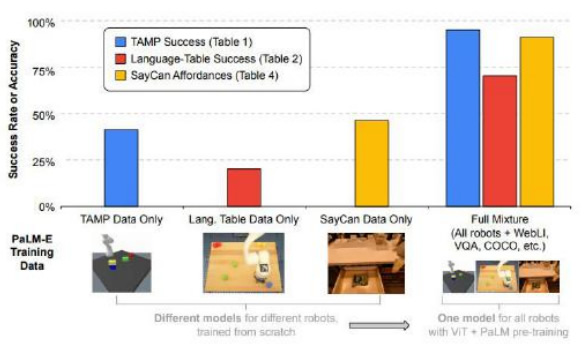
PaLM-E š╣╩Š┴╦┤¾─Żą═║═ÖCŲ„╚╦ĮY║ŽĄ─ųTČÓ┐╔─▄ąįĪŻęį┤¾─Żą═×ķ║╦ą─Ą─ PaLM-E ėą┴╦┴╝║├Ą─▀węŲ
īW┴Ģ─▄┴”Ż¼Å─Č°┐╔ęį═©▀^ūįų„īW┴ĢüĒ═Ļ│╔ķL┐ńČ╚ęÄäØĄ─╚╬䚯¼▒╚╚ńŻ¼Ī░Å─│ķīŽ└’─├│÷╩ĒŲ¼Ī▒▀@ŅÉ
╚╬äš░³└©┴╦ČÓéĆėŗäØ▓Į¾EŻ¼▓óŪęąĶ꬚{ė├ÖCŲ„╚╦özŽ±Ņ^Ą─ęĢėXĘ┤üĪŻĮø▀^Č╦ĄĮČ╦ė¢ŠÜĄ─ PaLM-E
┐╔ęįų▒ĮėÅ─Ž±╦žķ_╩╝ī”ÖCŲ„╚╦▀MąąęÄäØĪŻė╔ė┌─Żą═▒╗╝»│╔ĄĮę╗éĆ┐žųŲ╗ž┬ĘųąŻ¼╦∙ęįÖCŲ„╚╦į┌─├╩Ē
Ų¼Ą─▀^│╠ųąŻ¼ī”═ŠųąĄ─Ė╔ö_Š▀ėą¶ö░¶ąįĪŻ▓óŪęė╔ė┌Ųõ▓╔ė├┴╦ČÓ─ŻæBą┼Žóū„×ķ▌ö╚ļŻ¼ŽÓ▒╚ ChatGPT
for Robotics šō╬─ųąąĶę¬īółDŽ±ą┼Žó▐D╗»×ķ╬─ūų▌ö╚ļüĒšf─▄ē“½@╚ĪĖ³ČÓĄ─ą┼ŽóŻ¼Å─Č°╠ß╔²ÖCŲ„╚╦─Ż
ą═Ą─ąį─▄Ż¼─▄ē“æ¬ė├ĄĮĖ³ÅVĘ║Ą─ł÷Š░ųąĪŻ
|
